
How I write 1000s tests with little effort
The power of property-based testing

50% OFF - The Complete TDD course

Are you ready to master Clean Code, Testing and Test-Driven Development (TDD)?
I recently launched a complete TDD course containing everything you need to craft high-quality software.
Now there is a 50% OFF for the course
Get instant access by clicking here.
Motivation
The problem with normal unit tests is that it’s nearly impossible to cover all input combinations for your tested code. But property-based testing fixes this. It’s yet another testing type most people don’t know what it is. But if you learn it well, I can guarantee it will be one of your most important tools for writing quality software.
Property-based testing has helped my team many times to find bugs and boost our confidence in our software. I can't imagine working without it. In this post, I'll teach you what it is and how to use it in real-life projects. Let’s go!
What is it?
Property-based testing is a type of testing to check if our system holds a property when tested with a large number of inputs. Instead of writing individual test cases with specific inputs and expected outputs, you define business invariants - aka properties - that your code should always satisfy.
The testing framework then automatically generates a large number of random test cases to check if the properties hold true. With property-based testing, we can maximize the input scope coverage while optimizing the feature coverage.

Why to use it?
Property-based testing is a powerful tool for finding bugs in corner cases, edge cases, and unexpected input combinations that normal unit tests often miss. By generating a diverse set of inputs, it exposes your code to a broader range of scenarios, revealing hidden issues.
Beyond that, properties serve as a form of executable documentation, offering clear, formal descriptions of the expected behaviors of your code.
Real-life example
Consider a domain in logistics, specifically a function that calculates the shortest path between two cities. This function is crucial for optimizing delivery routes and minimizing transportation costs for a logistics company.
Before we start writing property-based tests, we need to think about the possible properties of the behavior. For our shortest path calculation function, we can define several properties, such as:
Symmetry: The shortest path from A to B should be the same as from B to A.
Non-Negativity: The calculated shortest path length should never be negative.
Consistency: The function should always return the same shortest path for the same start and destination cities.
Writing property-based tests
For testing purposes, we have 100 different cities represented in a graph. Each city is a node in the graph representation. The nodes are connected by edges that have cost assigned. A cost is the distance between two nodes.
The function signature for the shortest path looks as follows:
get_shortest_path(start_city: usize, dest_city: usize) -> (Path, Length)In our tests, we want to randomize three inputs to cover all possible input combinations:
The start city index
The destination city index
The distances between the cities
Property #1 - Symmetry
Now let’s see the property-based test for our first property, written in the Rust programming language. The property states that the shortest path from A to B should be the same as from B to A:

Let’s see what happens:
Line 32: First, we configure the test to generate up to 1000 test cases.
Line 35-36: We generate start and destination city indexes from 0 to 99 to randomize calculations for the 100 cities.
Line 37-39: We create a city graph with different distances between the edges. Here is the random_distances function that generates 100 random costs ranging from 1 to 200:


Line 41-42: We calculate the shortest path from A to B and from B to A
Line 44: Finally, we verify if the two paths have the same length, so the property holds true.
After writing the test, we can run it easily using the standard test command. It will generate 1000 different tests in each run, each with different randomized data. If there is an error, it will also display the input combination that caused the failure. It makes issues easily reproducible. Easy debugging for the win!
Property #2 - Non-Negativity
At this property, the test is quite similar; we just check if the shortest path is never negative.
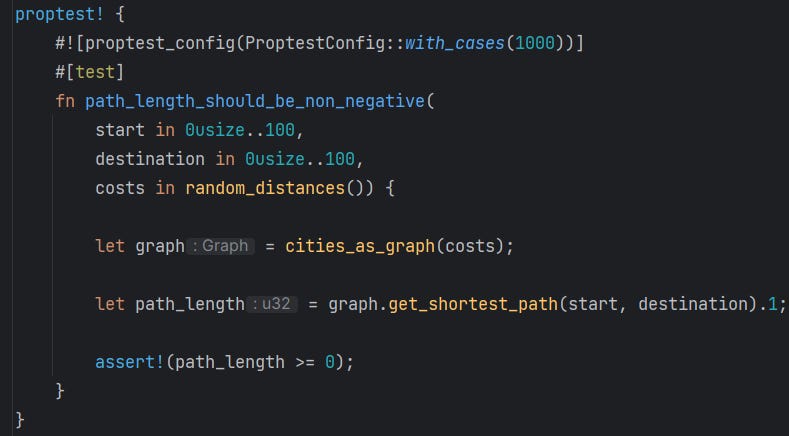
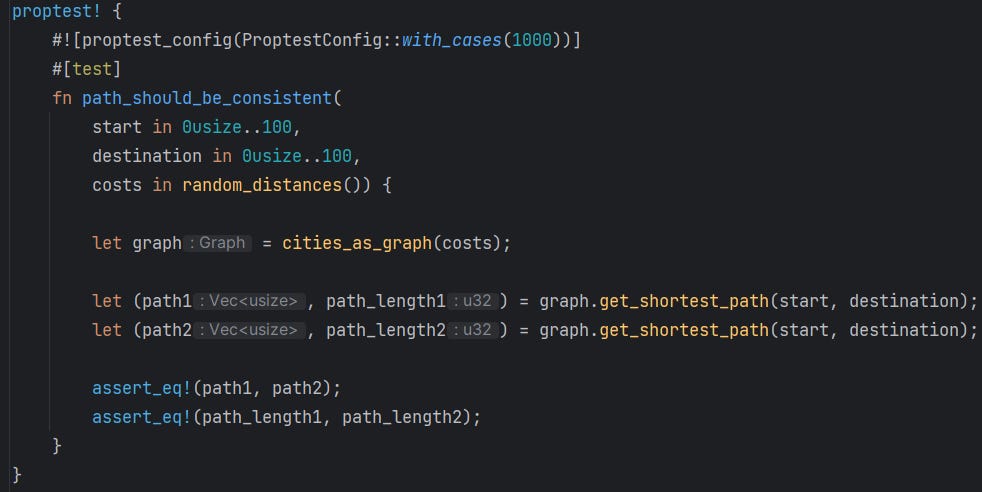
Property #3 - Consistency
At this property, we check that the shortest path calculation on the same input will always yield the same result:
What about normal unit tests?!
Now, imagine writing all these tests with traditional example-based unit tests. You would need to write thousands of them, which would be expensive to write and execute. Not to mention the maintenance cost they have once the behavior changes.
With property-based testing, we can maximize input coverage with randomized data while optimizing execution time. It's like having an army of testers working tirelessly to find hidden bugs. This approach not only saves time and resources but also uncovers edge cases you might never think of.
Tools in your tech stack
Of course, property-based testing isn’t limited to the Rust programming language. You can find similar libraries in many tech stacks, such as:
C#: FsCheck
Java: Jqwick
JavaScript: Fast-check
Python: Hypothesis
Swift: SwiftCheck
Rust: proptest
Conclusion
Property-based testing doesn’t replace unit testing. Rather, it provides an additional layer to increase confidence and remove boilerplate tests. By defining properties that must hold true for any input, we can automatically generate a wide range of test cases, ensuring that our implementation handles all scenarios correctly.
If you want to master testing, Test-Driven Development and Mutation Testing check out my recently launched complete TDD course, which includes:
The fundamentals of Test-Driven Development
Three real-world TDD examples in C#, TypeScript and Rust
The power of Mutation Testing
Using TDD to design high-quality software
Testing legacy code
Refactoring best practices
Get instant access by clicking here.
The sponsor of the week
This post is sponsored by Gregor Ojstersek, the author of Engineering Leadership newsletter having 60k+ subscribers.
The hardest transition for a senior developer is to become a tech lead. Why?! Because writing clean code is not enough. You need people skills. You need to know how to manage people. You need to understand the dynamics of a team and how to motivate individuals.
But here's the good news: now you can learn these skills easily.
My friend Gregor Ojstersek launching a cohort-based course, specifically for senior developers to become tech leaders.
Now he offers a 25% for the Craft Better Software readers. For more info, click here.
Interesting approach and well documented, thanks for sharing!
A slight tweak on this is combinatory testing - rather than using random values, we could use combinatorial sets generated from ranges.
I blogged about it here: https://conwy.co/articles/combinatorial-testing/
The combinatorial approach might be better when we want to cover functions with idiosyncratic input ranges.
Interesting. I’d like using this approach for some tests. The struggle would be in identifying rules that can be generalized in this way.